
After attending CFUnited 2009, my coworker and I came back with a few thoughts, including that we were way behind the CF community in our development and that it was time to explore and start utilizing frameworks. The presenters did a great job selling us on the idea that using a framework is the “best practice”. After looking at several, we choose to Mach-II framework, as it seemed fairly intuitive, easy to learn, and at first glance had great documentation and a newbie-friendly community (these last two facets, we sadly learned was not quite like we were thinking).
After tinkering with the example, we began using it for our new projects, two small applications, and a large, flagship application. For the most part, it has worked great, though of course the learning curve had us stressing and cussing for a while, as did the frustrations with the gaps in the documentation. However, we pressed on, and I think we're doing pretty well overall. The flagship application, AgriLife People (version 3), will be a seriously awesome replacement to our old employee directory and, through an API, will act as a “single sign on” type application for gaining entry into some of our other employee-focused applications.
Until last week, everything we built for it faithfully followed to Mach-II concept of a model, which each “object” having a listener, a gateway, a DAO, and a bean. Even our JSON callers went back into the model for everything. Again, until last week, this was fine. Sure, we'd sometimes we had to sit and hash out how to do something, but in the end, we figured it out and moved on. No real problems…until it was time to build the printable directory.
The directory is a bear…and one we cannot simply shoot and leave in the woods, because having the ability to print the multi-hundred page employee directory is part of the project specs. Never mind having a live, easily accessible website where you can find any email address, phone number, and office address (complete with beautifully done maps to the office that use jQuery with Google Maps). We must also have a printable directory, which is in PDF format. Now you might be thinking, what's so hard about a directory? One would initially think nothing…You just go get the people, get their contact details, and get their departments. Simple Gateway function. Spit out the results, wrap in CFDOCUMENT and done. We thought the same, even marking it as a 10-hour task our project plan. Oh, foolish us.
See, the complication arises when we look at the actual way the data that drives it all is structured and how it actually needs to be presented. First, we have what we call entities – the actual state agencies. AgriLife, an entity itself, is comprised of multiple entities …and those entities can theoretically have infinite entities under them, in an infinite hierarchy. Each of those entities have departments within them. Again, departments can have departments under them, in an infinite hierarchy. Now we have two hierarchies that have to be connected, recursively looped, and properly arranged in the directory (depending on the entity selected) in that hierarchical fashion.
If that were not bad enough, an employee can have multiple positions, with those positions being in any department in any entity (up to 100, if anyone were so insane – fortunately, just two is most common). So Person A could have Position Z in Department 4 in Entity 2, and Position Y in Department 2.2.1 under Entity 1. While they have only one email address, for each position they can have two addresses (office and shipping). Head hurt yet? A person-position relationship can also have an unlimited number of flags indicating special things about their position, such as their being associated with one of our core program areas (like 4-H), a county agent (for Extension folks), a support staff person, or a department head. Fortunately, we don't need all their roles for this directory, but we do need to retrieve the department heads for each department.
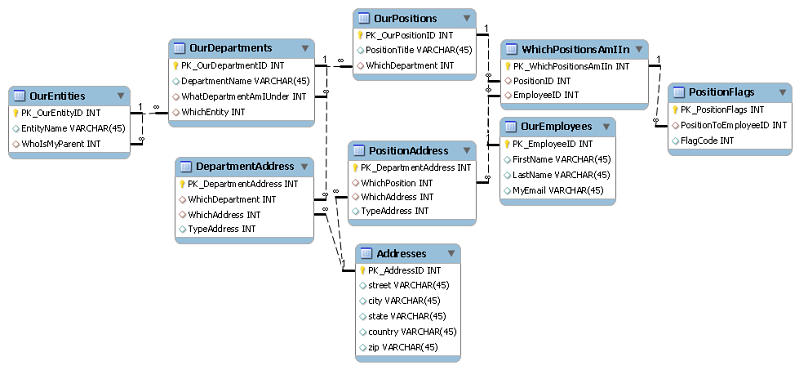
Figure 1: Basic ERD showing the generalized tables being discussed (obviously, this does not use my normal naming schema at all!)
With all that, and some more behind the scenes connectors not shown in my rough generalized ERD (Figure 1) – we are dealing with some 9-10 tables, some of which have to be tied together in multiple ways depending on where we are in the PDF. In that PDF, we need to have the selected entity, any departments under it, employees in those departments, child departments, employees of child departments (and so on), any child entities, and rinse repeat the departments/child departments for each of those child entities. Oh, and make sure the department details (they have their own addresses after all) show at the top for a department, with the department head noted. We did decide to eliminate some of the complexity by changing our initial plan of infinite levels of complexity to allow only two levels of entities and departments without a patch. However, even after that change, trying to figure out how to get all this data for outputting while sticking to the model had me banging my head against a wall.
Sure, I could conceivably have the listener call the Gateway and built out some hideous array or structure with all the data, but it would be insanely massive, and the resulting code to generate the PDF would also be insanely massive. It would also be horribly messy and ripe for problems all around. Honestly, my brain just wouldn't compute it…it told me I was nuts, that this was nuts, and it would NOT even attempt to try to wrap its head around how to build such a thing. Finally, my co-developer and I sat down and had a long discussion about this thing.
In the end, we realized the way to solve this problem of complexity was to remove some of the complexity, get out of the model, and return to some good, old-fashioned style ColdFusion. The page is still a “view” in Mach-II; however, the only thing coming out of the model is the entity Bean that has the details of the selected entity, pulling the datasource name, and calling in some global functions. Within that view, 28 queries (including four source queries that I then run all the rest off of to reduce overhead, and all cached every 12 hours), 14 CFLOOP, and 126 CFIFstatements. Pulling everyone we currently have in the DB (over 2000 folks) in over 300 departments in 3 entities, the resulting 241 page PDF takes just under 6 seconds to run on our development server once the queries are cached, and that's with our DB not being indexed yet.
So long post later, what does it mean? Am I going to advocate dumping Mach-II or frameworks? Nope. They work, and they work well. The main thing I took away from this lengthy experience was a much-needed reminder that you need to pick the right tool for the job. You could theoretically break up your driveway with a hammer and chisel, but it certainly isn't the most efficient way to do it and you will pay dearly for the effort versus a using jackhammer. Conversely, a jackhammer is a bad idea on dealing with a small bit of cement porch attached to your house, so you'd probably go with a sledgehammer a better idea.